Purpose This study evaluated the feasibility and performance of a deep learning approach utilizing the Korean Medical BERT (KM-BERT) model for the automated classification of underlying causes of death within national mortality statistics. It aimed to assess predictive accuracy throughout the cause-of-death coding workflow and to identify limitations and opportunities for further artificial intelligence (AI) integration.
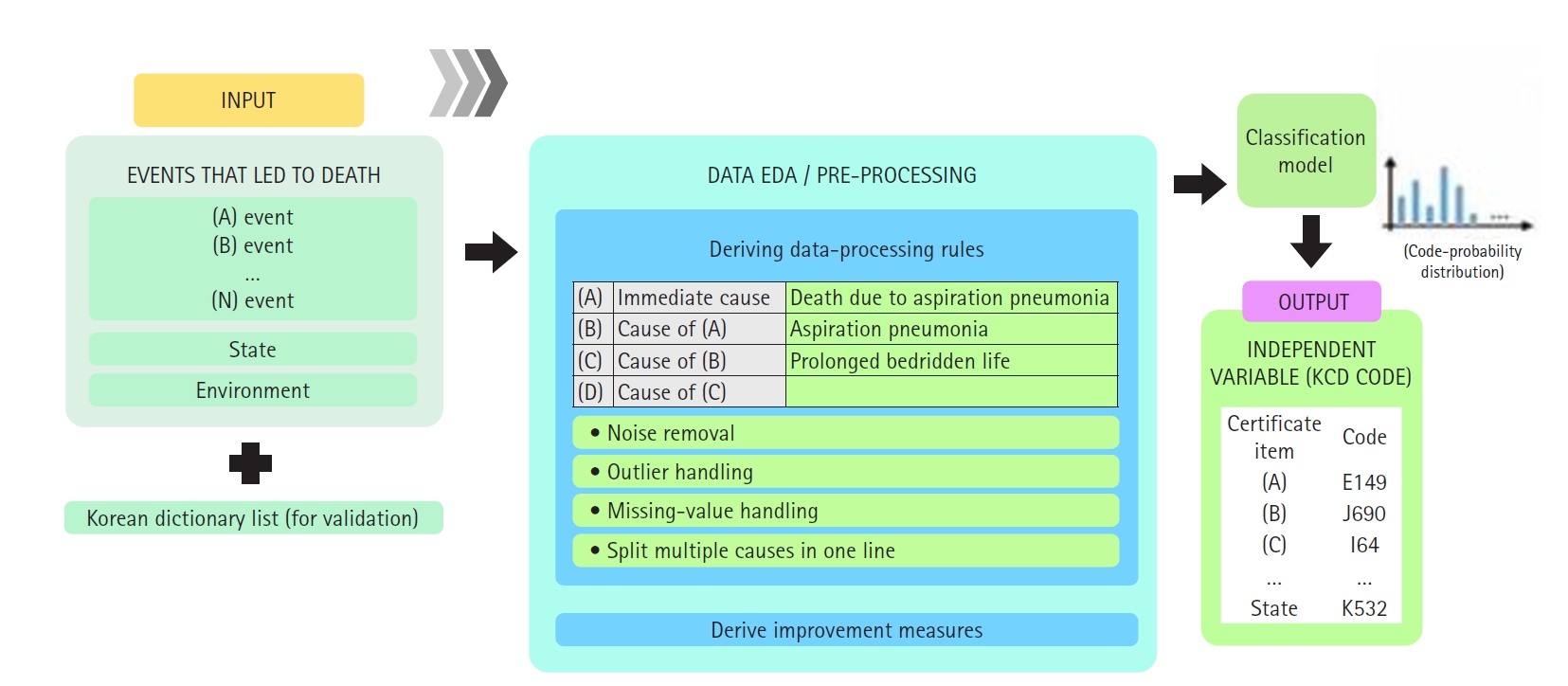
Methods We performed a retrospective prediction study using 693,587 death certificates issued in Korea between January 2021 and December 2022. Free-text fields for immediate, antecedent, and contributory causes were concatenated and fine-tuned with KM-BERT. Three classification models were developed: (1) final underlying cause prediction (International Classification of Diseases, 10th Revision [ICD-10] code) from certificate inputs, (2) tentative underlying cause selection based on ICD-10 Volume 2 rules, and (3) classification of individual cause-of-death entries. Models were trained and validated using 2021 data (80% training, 20% validation) and evaluated on 2022 data. Performance metrics included overall accuracy, weighted F1 score, and macro F1 score.
Results On 306,898 certificates from 2022, the final cause model achieved 62.65% accuracy (F1-weighted, 0.5940; F1-macro, 0.1503). The tentative cause model demonstrated 95.35% accuracy (F1-weighted, 0.9516; F1-macro, 0.4996). The individual entry model yielded 79.51% accuracy (F1-weighted, 0.7741; F1-macro, 0.9250). Error analysis indicated reduced reliability for rare diseases and for specific ICD chapters, which require supplementary administrative data.
Conclusion Despite strong performance in mapping free-text inputs and selecting tentative underlying causes, there remains a need for improved data quality, administrative record integration, and model refinement. A systematic, long-term approach is essential for the broad adoption of AI in mortality statistics.

 , Gyeongmin Im
, Gyeongmin Im First
First Prev
Prev